La herramienta está siendo desarrollada por un equipo de Meta y la Universidad Hebrea de Jerusalem
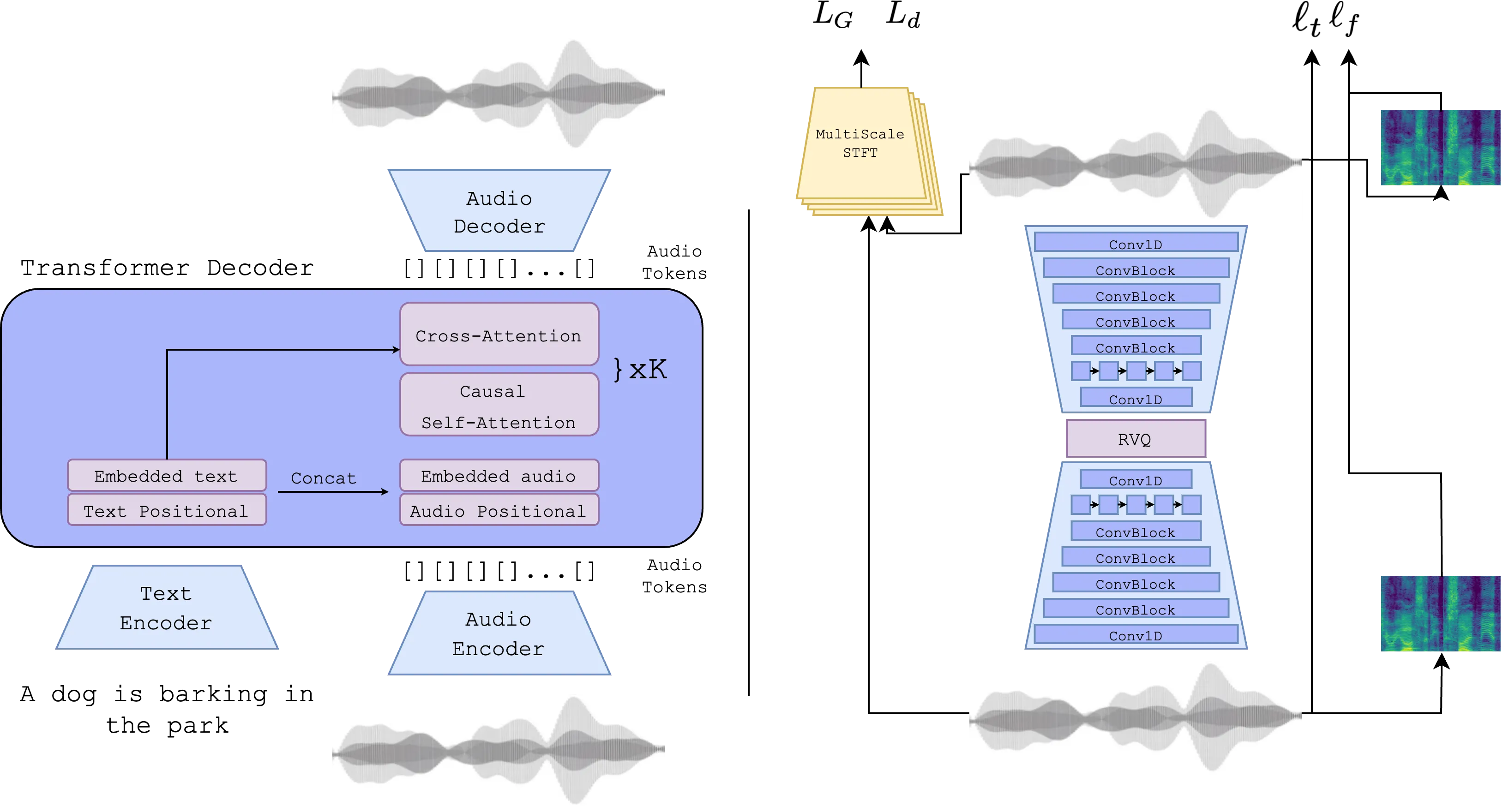
La Inteligencia Artificial está cobrando mayor importancia en gran variedad de actividades relacionadas con la producción de contenido. A las IAs que crean imágenes basadas en audio se ha sumado las que crean video, como la desarrollada por Meta. Sin embargo, también se ha creado una que tiene la capacidad de generar audio a partir de indicaciones de texto.

El nuevo programa fue creado por investigadores de Meta en conjunto con Yossi Adi, profesor de la Escuela de Ciencias de la Computación de la Universidad Hebrea de Jerusalem, como parte de un proyecto que genera, partiendo desde cero y solo con descripciones de texto, muestras de audio de algunos segundos de duración. Un inicio humilde para una herramienta que puede ser útil en el futuro.
Felix Kreuk, investigador en Meta, publicó un video en Twitter que presentó el pequeño resultado de la creación de esta Inteligencia Artificial a la que se puso a prueba con indicaciones como “silbando con viento”, “hombre hablando con muchas personas aplaudiendo en el fondo”, “hombre hablando seguido por otro hombre hablando de fondo mientras suena el motor de una motocicleta” y “hombre hablando mientras escribe en un teclado”.